https://www.linkedin.com/mypreferences/d/settings/data-for-ai-improvement
The ubiquity of email has made it the default aggregator of many sources of information that it wasn’t originally designed for. Email is the method by which services can push information to you. But it’s not ideal for carrying notifications, because there’s no way for a service to tell your email client that a notification has been read and to remove it from your inbox. This is a proposal for an API to use instead. It is called NotificationFeed.
To start with, NotificationFeed is based on JSON Feed. The primary change is strictly semantic. Since the feed content is defined as notifications, the absence of a previously present feed item shall signify that the item was read.
The feed may contain webhooks for marking items as read.
A URI scheme such as notificationfeed: will exist for initiating subscriptions in client apps.
Absence of a protocol was an original sin of RSS and podcasts. If not for the iTunes URI, I don’t know if podcasts would have gotten to where they are today.
Editorialization
For discoverability, the existence of a NotificationFeed can be announced like an RSS feed with a link tag in a webpage or email <head/>
<link rel="alternate" href="notificationfeed:example.com/notificationfeed" type="application/json+feed+notification">Or this may be done via JSON+LD Structured Data Markup.
It is assumed that authentication will be common, so a norm of using a good modern authentication method should be established.
Items may include webhooks for unsubscribing from categories of notifications.
Is it overly restrictive to limit this notifications? Could this be seen as an extension to JSON Feed use cases where server side read state is valuable?
Editorialization
Categories
My Linux Distro
Features I would put into a Linux distro if I made one.
grub-btrfs
I love the idea that if I screw something up, I can simply reboot to roll it back. AFAICT, I can’t retrofit this to my current Arch install, so I think this is a good thing to bake by default into the installer.
Also related to btrfs, the GUI tools snapper and timeshift can integrate into btrfs, but by default they rely on a certain conventional btrfs subvolume structure that I don’t have since my Arch install was just the default arch_install script, so fix that.
I like the idea of immutable OSes but in practice having to reboot after doing an install isn’t worth it. If I’m worried about screwing things up by installing something new, I’ll do it in a toolbox. So install that by default.
Also let’s install etckeeper by default. And I’d like a GUI that unifies all btrfs snapshots, timeshift/duplicity style backups, and etckeeper commits into one place so if I have an issue that I’m unsure about, I can see a timeline of changes and make a guess about what might have broken based on roughly when I think the breakage started.
WPS
I love the convenience of using WPS to set up my WiFi. I think the installer should nudge the user to use this since it creates the best case experience.
Repository Mirrors
I like to detect the closest/fastest repository mirror near me and use that. I like how easy Ubuntu makes it. I think it’s worth making it part of the installation process since it can be a single click skippable step that can really speed things up.
Net-install by default
I like net-install ISOs since they result in a totally up-to-date installation on first boot.
find-the-command
I like how when you try to run a program that you don’t have installed in Ubuntu, it tries to figure out what package provides that executable and recommends you install it. I have find-the-command installed in Arch, but it doesn’t work as well as in Ubuntu, at least as I have it set up right now.
Personalizations
Just stuff I like
fishshellsystem-load-indicatornushellpodmanandpodman-desktopgnome-boxesmicrotext editorunifontandnotofonts for Unicode coverage to avoid seeing �streencdu
Pre-configured software sources
If you use flatpak, 99% of the time you’re downloading the flatpaks from Flathub. If you use podman, 99% of the time you’re downloading the container images from Dockerhub. It’s annoying to have to do an extra step to configure these sources the first time. Just be real and configure them by default, or make it a single click affair to set them up.
Base
I currently use Arch, so that’s my top pick for a base. I really just like that with AUR and the popularity of Arch, Arch seems to give the best experience when I try to install whatever random new little project I find on Hacker News. And I’m happy with the rolling release model.
Categories
Refactoring
The process of gradually turning code into the code you would have written if you fully understood it all from the beginning
Categories
My ChatGPT Moment
I was struck by inspiration while browsing r/cocktails
So naturally I wanted to save this conversation to share. Screenshots, saving to HTML or printing all didn’t work. So I had the idea to search stack overflow for some javascript that could dump out the current state of the DOM. I found it and pasted it into my browser console. I got an error, so I figured let ChatGPT figure this out.
Thanks to our friends HTMX, Supabase, and a touch of some lesser known SQL, yes. Here’s how.
Supabase is exceedingly easy to get going with. I’ve yet to encounter a single source of friction in starting a basic project and setting up my database.
I created this dummy table with the foolproof GUI.
Then I populated some data.

Now here’s the magic. We can generate XML via our SQL query using Postgres’s XML functions. I’ve wrapped it in a function to make it easy to call.
This creates the following HTML
<table>
<th>Column 1</th>
<th>Column 2</th>
<tr>
<td>This content</td>
<td>came from a database</td>
</tr>
<tr>
<td>hosted on supabase</td>
<td>and populated via HTMX</td>
</tr>
</table>
| Column 1 | Column 2 |
|---|---|
| This content | came from a database |
| hosted on supabase | and populated via HTMX |
Simply by creating this function, Supabase automatically create an API for us using PostgREST. The API Docs section shows use exactly how to use it.
curl -X POST 'https://<my-project-id>.supabase.co/rest/v1/rpc/home' \ -H "Content-Type: application/json" \ -H "apikey: SUPABASE_KEY" \ -H "Authorization: Bearer SUPABASE_KEY"
Here’s the HTML of our web page which calls our function using HTMX
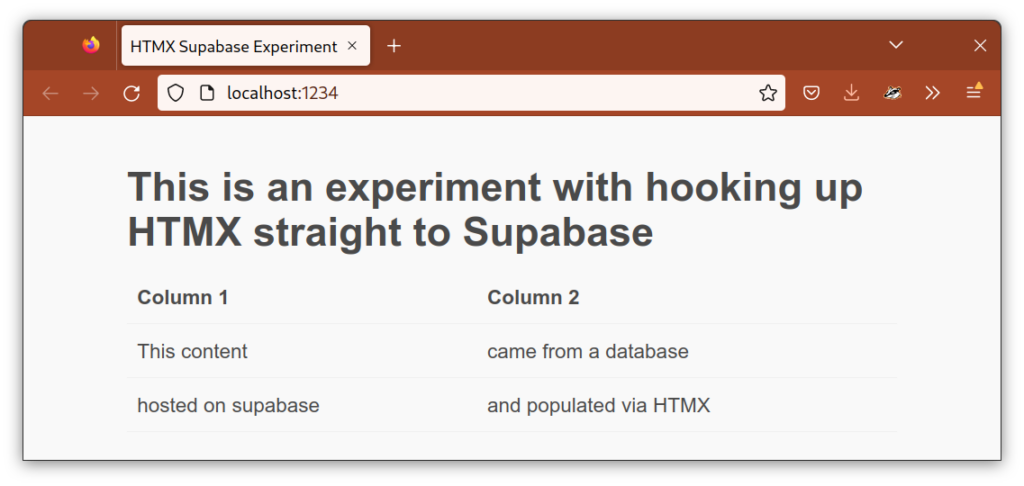
There was just one snag in this all, which is that Supabase currently only returns query results as JSON, so it wraps our HTML in quotes. Luckily HTMX offers hooks into its workings, via event handlers and stripping those quotes is trivial. But I plan to submit a feature request to Supabase. I figure they could omit the quotes when using the header Content-Type: application/xml. This particular use case of conflating HTML and XML might be considered hacky, but I think it’s very reasonable to want to create an XML API using Supabase and SQL XML functions.
Categories
Black Sands – Bonobo
I love this song. It’s like it was made specifically for me.
It features the clarinet, which I played as a kid. It does a good job showing of the range and timbre of the instrument, which is what really attracted me to it.
It has significant polyphony. I’m a huge sucker for that. It has this kind of swaying, braiding, one-over-the-other feel that resonates with me as a skater and skier.
The syncopation in the drums I love. Really groovy.
It very gradually swells adding in more and more layers. I love this in a song. Where it changes so gradually you don’t really notice at the time. But at some point you look back and it’s changed so much. What a metaphor for life!
Categories
Some Deep git Trivia
A typo lead me down a little rabbit hole today.
The typo was git pul instead of git pull
~ git pul
git: 'pul' is not a git command. See 'git --help'.
The most similar commands are
pull
spullgit spull? That sounds funny. What does that do? Google results for it are disappointing. (Ripe SEO for this blog post).
~ git spull --help
'spull' is aliased to 'svn rebase'Hmm… How do I list all my aliases?
~ git alias --help
'alias' is aliased to '!git config --list | grep 'alias\.' | sed 's/alias\.\([^=]*\)=\(.*\)/\1\ => \2/' | sort'Hmm…
~ git alias
a => !git add . && git status
aa => !git add . && git add -u . && git status
ac => !git add . && git commit
acm => !git add . && git commit -m
alias => !git config --list | grep 'alias\.' | sed 's/alias\.\([^=]*\)=\(.*\)/\1\ => \2/' | sort
au => !git add -u . && git status
c => commit
ca => commit --amend
cm => commit -m
d => diff
l => log --graph --all --pretty=format:'%C(yellow)%h%C(cyan)%d%Creset %s %C(white)- %an, %ar%Creset'
lg => log --color --graph --pretty=format:'%C(bold white)%h%Creset -%C(bold green)%d%Creset %s %C(bold green)(%cr)%Creset %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative
ll => log --stat --abbrev-commit
llg => log --color --graph --pretty=format:'%C(bold white)%H %d%Creset%n%s%n%+b%C(bold blue)%an <%ae>%Creset %C(bold green)%cr (%ci)' --abbrev-commit
master => checkout master
s => status
spull => svn rebase
spush => svn dcommitSo if you like to create short little aliases, think about using some of these built in ones instead so they’ll be pre-configured for you everywhere.
I like to use a gui for viewing history, but git l, git ll, git lg and git llg are pretty nice.
I also tried
~ git spull
Can't locate SVN/Core.pm in @INC (you may need to install the SVN::Core module) (@INC contains: /usr/local/git/share/perl5 /Library/Perl/5.18/darwin-thread-multi-2level /Library/Perl/5.18 /Network/Library/Perl/5.18/darwin-thread-multi-2level /Network/Library/Perl/5.18 /Library/Perl/Updates/5.18.4 /System/Library/Perl/5.18/darwin-thread-multi-2level /System/Library/Perl/5.18 /System/Library/Perl/Extras/5.18/darwin-thread-multi-2level /System/Library/Perl/Extras/5.18 .) at /usr/local/git/share/perl5/Git/SVN/Utils.pm line 6.
BEGIN failed--compilation aborted at /usr/local/git/share/perl5/Git/SVN/Utils.pm line 6.
Compilation failed in require at /usr/local/git/share/perl5/Git/SVN.pm line 25.
BEGIN failed--compilation aborted at /usr/local/git/share/perl5/Git/SVN.pm line 32.
Compilation failed in require at /usr/local/git/libexec/git-core/git-svn line 22.
BEGIN failed--compilation aborted at /usr/local/git/libexec/git-core/git-svn line 22.Interesting. So git has some SVN functionality partially built in but it depends on some perl modules.
So that’s just an interesting exploration into some functionality built into git that you might not know existed.
Problem
You’re at dinner with a group of friends. Everyone knows how much their meal cost. You have to add up each person’s meal cost to get a total.
- You: $11
- Alice: $10
- Bob: $12
- Claire: $13
Procedural
You call out to each person and ask them how much their meal cost. As they answer, you write on a piece of paper.
11 + 10 = 21
21 + 12 = 33
33 + 13 = 46
Object-Oriented
You have a calculator. You announce to everyone to key in their meal cost. You key in 11. You give the calculator to Alice. When Claire hands it to you it reads 46.
Functional
You: Alice, what was the total for you and everyone to your left?
Alice: Bob, what was the total for you and everyone to your left?
Bob: Claire, what was the total for you and everyone to your left?
Claire: What was the total for you and everyone to your left?
You: $11 Claire
Clair: $24 Bob
Bob: $36 Alice
Alice: $46
As ubiquitous as the web is, it is not currently as democratic as I suspect its early creators anticipated it would be. In particular, creating an extremely basic text based website is complicated enough that the rising generation Z tends to either rely on a social media platform, or they resort to creating their content as images. Text as images is terribly inaccessible for the blind. It can’t be easily searched or copied and pasted. The beauty of digital formats has given way to analog style degradation by way of lossy image compression.
There is a way to make a basic website quickly and easily for free with no skills necessary. I have dog-fooded it and documented it here.
GitHub is owned by Microsoft, so you’re still dependent on a tech giant. You do have to sign away your soul a little to create the GitHub account. But they don’t add any crap to around your content like cookies or pop-ups to use the mobile app. They don’t require readers of your content to create an account. I think this is a pretty good trade-off for most people. I’m sure there are plenty of other ways to get a similar basic site up, but I think the stability, reliability and dependability of GitHub, and the robust hosting you’ll get makes this a pretty sweet solution overall.